Gen AI LMM Training: Designing Safer, Smarter AI Interactions
Gen AI LMM Training: Designing Safer, Smarter AI Interactions
Gen AI LMM Training: Designing Safer, Smarter AI Interactions
Overview
Overview
To support the rapid development of a large language model (LLM), our team was tasked with scaling high-quality training data across diverse use cases—from factual Q&A to creative and conversational prompts. The key challenge was reducing the model’s high hallucination rate (>90%) while improving the safety, clarity, and consistency of its outputs.
To support the rapid development of a large language model (LLM), our team was tasked with scaling high-quality training data across diverse use cases—from factual Q&A to creative and conversational prompts. The key challenge was reducing the model’s high hallucination rate (>90%) while improving the safety, clarity, and consistency of its outputs.
My Role
My Role
As a Conversation Designer, I applied UX thinking to train a generative AI model through scalable prompt design. I independently created and refined hundreds of prompt-response pairs, achieving 100k+ prompt-response pairs as a team and a 10/10.25 average writing score while reducing hallucinations from 90% to <1%. I led prompt tuning across 45+ content categories, bringing structure, clarity, and user-centered tone to LLM outputs. My work directly improved AI usability, factuality, and safety, and helped accelerate model development across multiple high-impact use cases.
As a Conversation Designer, I applied UX thinking to train a generative AI model through scalable prompt design. I independently created and refined hundreds of prompt-response pairs, achieving 100k+ prompt-response pairs as a team and a 10/10.25 average writing score while reducing hallucinations from 90% to <1%. I led prompt tuning across 45+ content categories, bringing structure, clarity, and user-centered tone to LLM outputs. My work directly improved AI usability, factuality, and safety, and helped accelerate model development across multiple high-impact use cases.
Project Type
Project Type
AI Training, Prompt Engineering, UX Writing, Conversation Design, B2C
AI Training, Prompt Engineering, UX Writing, Conversation Design, B2C
Team
Team
2 Project Managers, 20 Conversation Designers/Prompt Engineers
2 Project Managers, 20 Conversation Designers/Prompt Engineers
Tools
Tools
Learning Management System (LMS), LLM Interface, Internal Writing Guidelines
Learning Management System (LMS), LLM Interface, Internal Writing Guidelines
Timeline
Timeline
22 weeks
22 weeks
Client
Client
Global Tech Company
Global Tech Company
** Due to honoring the terms of my confidentiality agreements, the artifacts have been reconstructed and should be considered as illustrative. All examples have also been scrubbed for PII and sensitive details.
** Due to honoring the terms of my confidentiality agreements, the artifacts have been reconstructed and should be considered as illustrative. All examples have also been scrubbed for PII and sensitive details.
** Due to honoring the terms of my confidentiality agreements, the artifacts have been reconstructed and should be considered as illustrative. All examples have also been scrubbed for PII and sensitive details.
Impact
Impact
translating to constant high performance across thousands of prompts
translating to constant high performance across thousands of prompts
9.5/10 writing score
9.5/10 writing score
9.5/10 writing score
reduced LLM hallucination from 90% to >1%
reduced LLM hallucination from 90% to >1%
Near-zero %
Near-zero %
Near-zero %
prompt-response pairs in 12 weeks
prompt-response pairs in 12 weeks
prompt-response pairs in 12 weeks
100k+ optimized
100k+ optimized
100k+ optimized
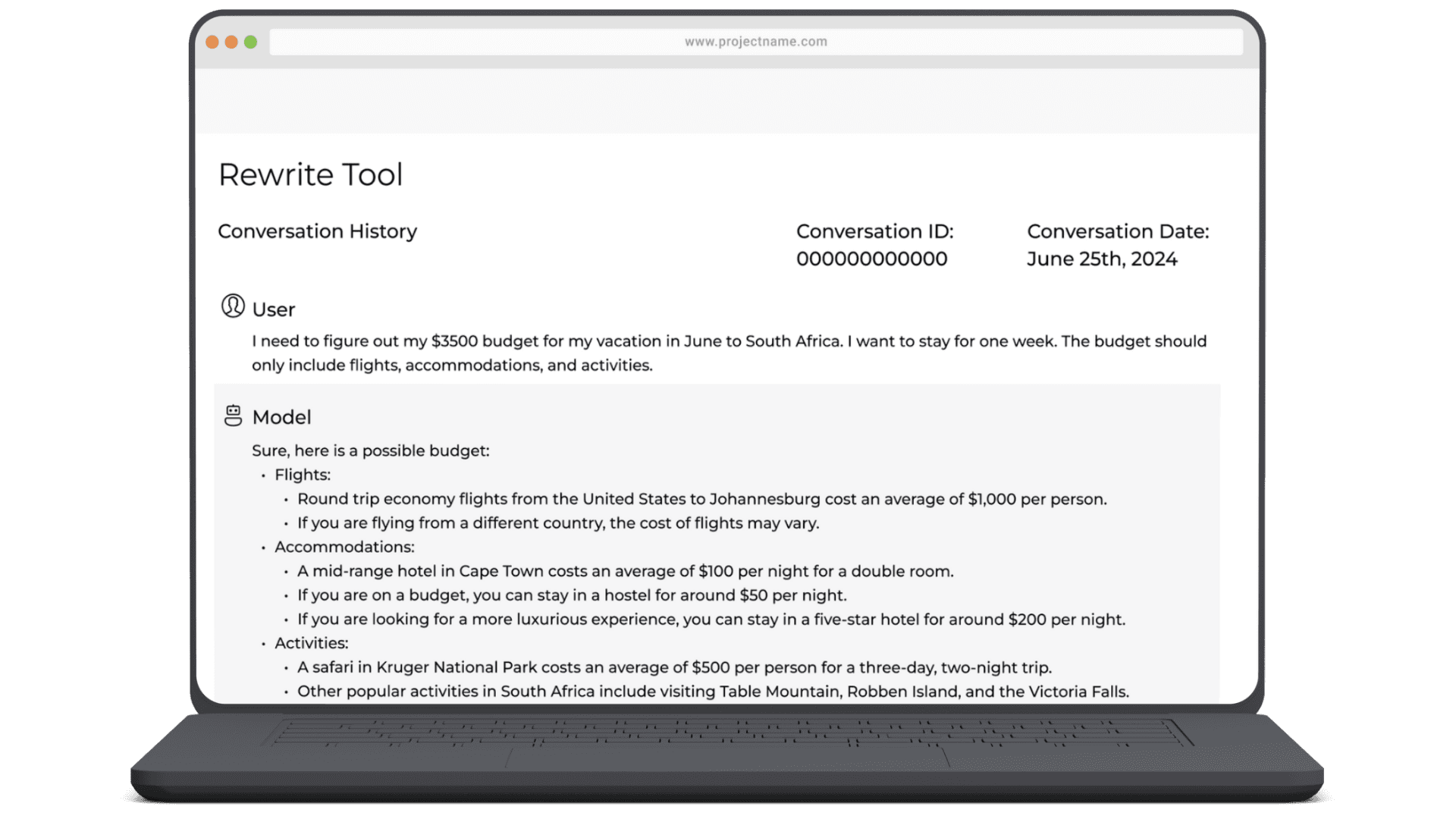
Before the LLM began producing responses, I created prompts and drafted my own replies to test early tone and style guidelines. This hands-on approach gave me a deep understanding of what made a response feel natural, informative, and safe. It also surfaced early challenges—hallucinations, awkward phrasing, and inconsistent, vague tone—which helped shape our rewrite standards moving forward.
Before the LLM began producing responses, I created prompts and drafted my own replies to test early tone and style guidelines. This hands-on approach gave me a deep understanding of what made a response feel natural, informative, and safe. It also surfaced early challenges—hallucinations, awkward phrasing, and inconsistent, vague tone—which helped shape our rewrite standards moving forward.
As internal guidelines evolved, I also iterated fast—ensuring every rewrite balanced clarity, creativity, and compliance to guide the LLM toward better human-like output.
As internal guidelines evolved, I also iterated fast—ensuring every rewrite balanced clarity, creativity, and compliance to guide the LLM toward better human-like output.
My overall goal throughout this project involved writing natural, clear prompts, assessing LLM-generated replies, and optimizing content against six evaluation categories and three prompt types:
My overall goal throughout this project involved writing natural, clear prompts, assessing LLM-generated replies, and optimizing content against six evaluation categories and three prompt types:
My overall goal throughout this project involved writing clear prompts, assessing LLM-generated replies, and optimizing content against six evaluation categories and three prompt types:
Applied human-centered design to craft, rewrite, and fine-tune Gen AI interactions using evolving internal guidelines and instruction-tuned frameworks
Applied human-centered design to craft, rewrite, and fine-tune Gen AI interactions using evolving internal guidelines and instruction-tuned frameworks
Applied human-centered design to craft, rewrite, and fine-tune Gen AI interactions using evolving internal guidelines and instruction-tuned frameworks
Phase 1: Prompt Authoring & Early-Stage Testing
Phase 1: Prompt Authoring & Early-Stage Testing
Phase 1: Prompt Authoring & Early-Stage Testing
Use Cases/Prompt Types
Instruction-tuned: Write the prompts i.e “Summarize a text for x”, get the generated response and rewrite that improving on all categories.
Prompt-Response tuning: Rewrite/Write a prompt or the LLM’s generated response to improve any or all of the categories.
Factual Dialogue tuning: Rewrite/Write the LLM’s generated response uniquely by verifying factual information, correcting hallucinations and plagiarism.
Description
No claiming consciousness or emotion. Adhere to no violence, certain, and inclusive use of language
Informative and non-plagiarized content
Check responses are factually correct and without contradictions
Original content, diverse language and names
Grammatically correct responses and no spelling errors
1st Person, neutral, polite, casual, and approachable
Improve
Safety
Information
Factuality
Creativity
Grammar & Spelling
Format & Style
Category
1
2
3
4
5
6
Description
No claiming consciousness or emotion. Adhere to no violence, certain, and inclusive use of language
Informative and non-plagiarized content
Check responses are factually correct and without contradictions
Original content, diverse language and names
Grammatically correct responses and no spelling errors
1st Person, neutral, polite, casual, and approachable
Improve
Safety
Information
Factuality
Creativity
Grammar & Spelling
Format & Style
Category
1
2
3
4
5
6
Use Cases/Prompt Types
Instruction-tuned: Write the prompts i.e “Summarize a text for x”, get the generated response and rewrite that improving on all categories.
Prompt-Response tuning: Rewrite/Write a prompt or the LLM’s generated response to improve any or all of the categories.
Factual Dialogue tuning: Rewrite/Write the LLM’s generated response uniquely by verifying factual information, correcting hallucinations and plagiarism.
Phase 2: Scaling & Real-Time Rewrites
Phase 2: Scaling & Real-Time Rewrites
Phase 2: Scaling & Real-Time Rewrites
As the LLM began generating outputs, I shifted into high-velocity production. At the start, the LLM hallucinated up to 90% of the time—frequently inventing facts, repeating content, or presenting contradictory information. Internal guidelines evolved daily, often requiring full rewrites, required fact-checking, creative rewriting, and safety alignment.
As the LLM began generating outputs, I shifted into high-velocity production. At the start, the LLM hallucinated up to 90% of the time—frequently inventing facts, repeating content, or presenting contradictory information. Internal guidelines evolved daily, often requiring full rewrites, required fact-checking, creative rewriting, and safety alignment.
As the LLM began generating outputs, I shifted into high-velocity production. At the start, the LLM hallucinated up to 90% of the time—frequently inventing facts, repeating content, or presenting contradictory information. Internal guidelines evolved daily, often requiring full rewrites, required fact-checking, creative rewriting, and safety alignment.
Navigated hallucinations, shifting standards, and high-output demands by building scalable writing systems and real-time fact-checking workflows.
Navigated hallucinations, shifting standards, and high-output demands by building scalable writing systems and real-time fact-checking workflows.
Navigated hallucinations, shifting standards, and high-output demands by building scalable writing systems and real-time fact-checking workflows.
I analyzed errors across use cases—like summaries, conversations, and content generation—and documented recurring issues in tone, grammar, and style. These findings shaped my rewrite strategies and helped refine our guidelines.
I analyzed errors across use cases—like summaries, conversations, and content generation—and documented recurring issues in tone, grammar, and style. These findings shaped my rewrite strategies and helped refine our guidelines.
I analyzed errors across use cases—like summaries, conversations, and content generation—and documented recurring issues in tone, grammar, and style. These findings shaped my rewrite strategies and helped refine our guidelines.

To keep pace with shifting guidelines, I developed reusable templates and workflows to maintain quality under tight timelines. When real user prompts were introduced, I leaned on tone nuance and factual accuracy to deliver responses that felt trustworthy and relevant. The team also built a quick fact-verification routine that helped me respond faster while maintaining high standards and a peer-checking system.
To keep pace with shifting guidelines, I developed reusable templates and workflows to maintain quality under tight timelines. When real user prompts were introduced, I leaned on tone nuance and factual accuracy to deliver responses that felt trustworthy and relevant. The team also built a quick fact-verification routine that helped me respond faster while maintaining high standards and a peer-checking system.
To keep pace with shifting guidelines, I developed reusable templates and workflows to maintain quality under tight timelines. When real user prompts were introduced, I leaned on tone nuance and factual accuracy to deliver responses that felt trustworthy and relevant. The team also built a quick fact-verification routine that helped me respond faster while maintaining high standards and a peer-checking system.

I wrote and revised thousands of prompt-response pairs spanning 45+ use cases, from summaries to creative storytelling.
I wrote and revised thousands of prompt-response pairs spanning 45+ use cases, from summaries to creative storytelling.
I wrote and revised thousands of prompt-response pairs spanning 45+ use cases, from summaries to creative storytelling.

Phase 3: Tuning for Tone, Factuality, and Safety
Phase 3: Tuning for Tone, Factuality, and Safety
Phase 3: Tuning for Tone, Factuality, and Safety
In the final stretch, my focus turned to refinement. The model had improved, but responses still needed polishing—removing minor hallucinations, tightening grammar, and aligning tone with user expectations
In the final stretch, my focus turned to refinement. The model had improved, but responses still needed polishing—removing minor hallucinations, tightening grammar, and aligning tone with user expectations
Iterated on prompt tuning strategies to address hallucinations, plagiarism, and user clarity
Iterated on prompt tuning strategies to address hallucinations, plagiarism, and user clarity
Iterated on prompt tuning strategies to address hallucinations, plagiarism, and user clarity
Internal safety and writing guidelines kept constantly evolving. Real user prompts also became the norm, so as I transitioned to “prompt tuning” and “factual dialogue tuning,” I shifted my focus to verifying claims, correcting specific hallucinations, and refining tone.
Internal safety and writing guidelines kept constantly evolving. Real user prompts also became the norm, so as I transitioned to “prompt tuning” and “factual dialogue tuning,” I shifted my focus to verifying claims, correcting specific hallucinations, and refining tone.
Outcome
Outcome
Achieved an average writing score of 9.5/10.25, surpassing team benchmarks. Writing scores measured efficiency and quality.
Achieved an average writing score of 9.5/10.25, surpassing team benchmarks. Writing scores measured efficiency and quality.
Reduced LLM hallucination rate dramatically — outputs became consistently safe, factual, and human-like.
Reduced LLM hallucination rate dramatically — outputs became consistently safe, factual, and human-like.
Enhanced user experience with responses that were engaging, trustworthy, and easy to understand.
Enhanced user experience with responses that were engaging, trustworthy, and easy to understand.
Impacted client satisfaction and the LLM’s development speed by delivering consistently high-quality training data.
Impacted client satisfaction and the LLM’s development speed by delivering consistently high-quality training data.

Reflection & Learnings
Reflection & Learnings
Reflection & Learnings
This project deepened my understanding of designing with and for AI. I learned how to bring UX rigor into a cross-functional, ambiguous space—balancing constraints, user needs, and emerging guidelines.
I worked closely with managers and peer designers/prompt engineers to share findings, align on safety updates, and improve consistency across prompt types. Our collaboration led to a shared prompt library, faster rewrite workflows, and stronger internal quality benchmarks for content creation and review.
I also developed a deep understanding of prompt engineering, ethical considerations in AI outputs, and how UX strategy and writing excellence play a foundational role in human-AI interaction design. Most of all, I learned how to scale content systems for fast-moving AI environments—without sacrificing usability, responsibility, or impact.
This project deepened my understanding of designing with and for AI. I learned how to bring UX rigor into a cross-functional, ambiguous space—balancing constraints, user needs, and emerging guidelines.
I worked closely with managers and peer designers/prompt engineers to share findings, align on safety updates, and improve consistency across prompt types. Our collaboration led to a shared prompt library, faster rewrite workflows, and stronger internal quality benchmarks for content creation and review.
I also developed a deep understanding of prompt engineering, ethical considerations in AI outputs, and how UX strategy and writing excellence play a foundational role in human-AI interaction design. Most of all, I learned how to scale content systems for fast-moving AI environments—without sacrificing usability, responsibility, or impact.
The TLD;r
The TLD;r
Learned how to apply UX thinking to AI training and conversation design at scale.
Learned how to apply UX thinking to AI training and conversation design at scale.
1
Balance clarity, safety, and creativity under rapidly evolving standards
Balance clarity, safety, and creativity under rapidly evolving standards
2
Collaborate cross-functionally with managers and designers
Collaborate cross-functionally with managers and designers
4
Fact-check and write high-quality content efficiently
Fact-check and write high-quality content efficiently
3
NEXT
NEXT

DocuCare: Empowering School Nurses through Better Documentation
A tracking tool born from the vision to not only facilitate but also illuminate the critical work of school nurses.
Read Case Study
Moodlets: Mobile App that Shows Emotional Patterns & Connects Mental Health Support
A highly functional tool that brings a new level of insight into personal emotional trends and facilitates connections with health professionals.
Read Case Study
Read Case Study
ReWA: A Visual Strategy to Promote Family & Community Empowerment
A modern, cohesive, and impactful visual identity that authentically reflects the mission of Refugee Women's Alliance—supporting refugee and immigrant women and their families.

Read Case Study
Moodlets: Mobile App that Shows Emotional Patterns & Connects Mental Health Support
A highly functional tool that brings a new level of insight into personal emotional trends and facilitates connections with health professionals.
Read Case Study
ReWA: A Visual Strategy to Promote Family & Community Empowerment
A modern, cohesive, and impactful visual identity that authentically reflects the mission of Refugee Women's Alliance—supporting refugee and immigrant women and their families.